一般化線形混合モデル(GLMM)とA/Bテスト:サンプルサイズが少ない場合
一般的に、A/B テストは大量のデータをもとに従来の統計的有意性を確認する「頻度論的アプローチ」に適しているが、以下のような状況ではサンプルサイズが十分に得られず、テストの信頼性が確保されにくいことがある:
- テスト期間が限られている場合
- 製品開発の初期段階
- ニッチ市場でのテスト
- 広範囲にデータを集めることが難しい予備テストフェーズ
これらの場合、サンプルサイズが制限された状況での分析には、MCMC などの「ベイズアプローチ」が有効となる。
この記事では、ベイズ統計と一般化線形混合モデル(GLMM)を使い、Python と NumPyro を活用して、A/B テストのテスト群(TG)とコントロール群(CG)間の効果の違いを解析する方法を説明する。
■ モデルの定義と数式
GLMM では、固定効果とランダム効果を組み合わせ、個々データ点の異質性を捉えることができる。
TG と CG の効果を比較するためのモデルは次のように定義される。
\[ \theta_i = b + r_i \] \[ \mu_i = \exp(\theta_i) \]
ここで、
- \(\theta_i\):線形予測子(固定効果とランダム効果を合わせた結果)
- \(b = \beta_0 + \beta_1 x_i\):固定効果(\(x_i\) は A/B を示すインジケーター)
- \(r_i \sim N(0, s)\):各ユーザー特有のランダム効果(正規分布から発生する個体差)
- \(\mu_i\):ポアソン分布のパラメータ(リンク関数に \(\theta\) の指数関数を取ることで非負の値となる)
ポアソン分布のパラメータである \(\mu_i\) は、リンク関数として \(\exp\) 関数を使用して \(\theta_i\) から変換される。
■ Python スクリプトの実装
以下のスクリプトでは、TG と CG のデータを生成し、それぞれの群における介入の効果を分析・可視化する。このプロセスを通じて、サンプルサイズが限られている場合に、ベイズ統計がどのように有効活用できるかを示す。
# ライブラリ等
import numpyro
import numpyro.distributions as dist
import jax
import arviz as az
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%config InlineBackend.figure_format = 'retina'◆ サンプルデータの生成
TG は介入により効果が大きくなることを仮定し、その効果を数値化する。
# 乱数のシードを設定
np.random.seed(42)
# ユーザー数の定義
num_users = 200
# ユーザーがテスト群(TG=1)かコントロール群(CG=0)かを決定
group = np.random.binomial(1, 0.5, size = num_users)
# 購入強度を定義(TGは1.5倍の購入強度)
cv_intensity = 1.5 * group + 1
# 負の二項分布による購入回数を生成
cv_count = np.random.negative_binomial(n = 10, p = 1 / (1 + cv_intensity), size = num_users)
# データフレームの作成
data = pd.DataFrame({
'group': group,
'cv_count': cv_count
})出力イメージは以下
data.head()| group | cv_count | |
|---|---|---|
| 0 | 0 | 4 |
| 1 | 1 | 20 |
| 2 | 1 | 37 |
| 3 | 1 | 41 |
| 4 | 0 | 6 |
サンプルサイズが200である全ユーザーについて、group = 1 のときは施策介入のあった TG であり、その場合の CV 数が多い状態でデータ生成されている。
◆ モデル設計と MCMC
NumPyro を使って、上記の通り定義された DataFrame data を基にした MCMC 処理を行う。
# モデル設計
def model(cv_count = None, group = None, num_users = 0):
beta0 = numpyro.sample('beta0', dist.Normal(0, 1))
beta1 = numpyro.sample('beta1', dist.Normal(0, 1))
s = numpyro.sample('s', dist.Exponential(1))
b = beta0 + beta1 * group
r = numpyro.sample('r', dist.Normal(0, s), sample_shape = (num_users,))
theta = b + r
mu = jax.numpy.exp(theta)
with numpyro.plate('data', num_users):
numpyro.sample('obs', dist.Poisson(mu), obs = cv_count)
# MCMC 処理
nuts = numpyro.infer.NUTS(model)
mcmc = numpyro.infer.MCMC(nuts, num_warmup = 500, num_samples = 2000, num_chains = 4)
mcmc.run(jax.random.PRNGKey(42), cv_count = data['cv_count'].values, group = data['group'].values, num_users = len(data))
mcmc_samples = mcmc.get_samples()◆ モデル診断
事後分布のトレースプロットを可視化し、MCMC サンプリングが適切に収束しているか確認する。
# モデル診断(視診)
idata = az.from_numpyro(mcmc)
az.plot_trace(idata)
plt.show()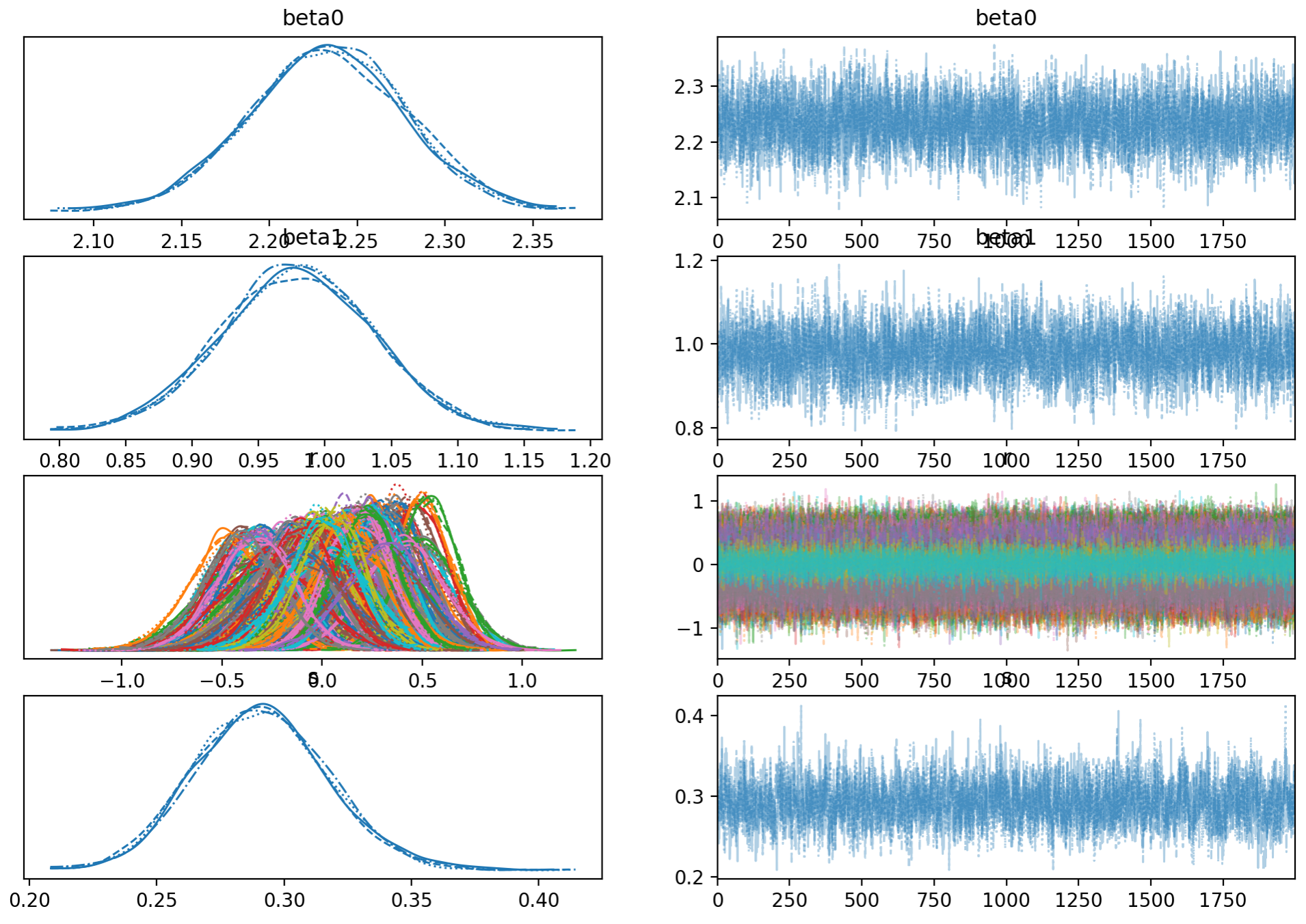
形状的に問題なさそう。(MCMC は無事に収束している。)
◆ 個別サンプルの出力確認
最初の10人のユーザーについて、分布を個別にプロットし、それぞれ観測されたCV数(cv_count)に赤線を引いて、実際のデータとの比較を行う。これにより、モデルがどの程度実データを再現できているか視覚的に評価する。
# MCMC 実行後のサンプルから beta0, beta1, s, r を取得
beta0_samples = mcmc_samples['beta0']
beta1_samples = mcmc_samples['beta1']
s_samples = mcmc_samples['s']
r_samples = mcmc_samples['r']
# ポアソン分布の平均 mu を計算
b_samples = beta0_samples[:, None] + beta1_samples[:, None] * group
theta_samples = b_samples + r_samples
mu_samples = jax.numpy.exp(theta_samples)
# ポアソン分布から obs をサンプリング
obs_samples = np.random.poisson(mu_samples)
# 確認のため、obs_samples の形状を出力
print("Shape of 'obs' samples:", obs_samples.shape)
# 可視化
fig = plt.figure(figsize = (12, 12))
for k in range(10): # 最初の20ユーザーをプロット
ax = fig.add_subplot(10, 2, k + 1)
az.plot_dist(obs_samples[:, k])
ax.axvline(cv_count[k], color = 'r', linestyle = 'dashed')
ax.set_title('User ID = {}'.format(k))
plt.tight_layout()
plt.show()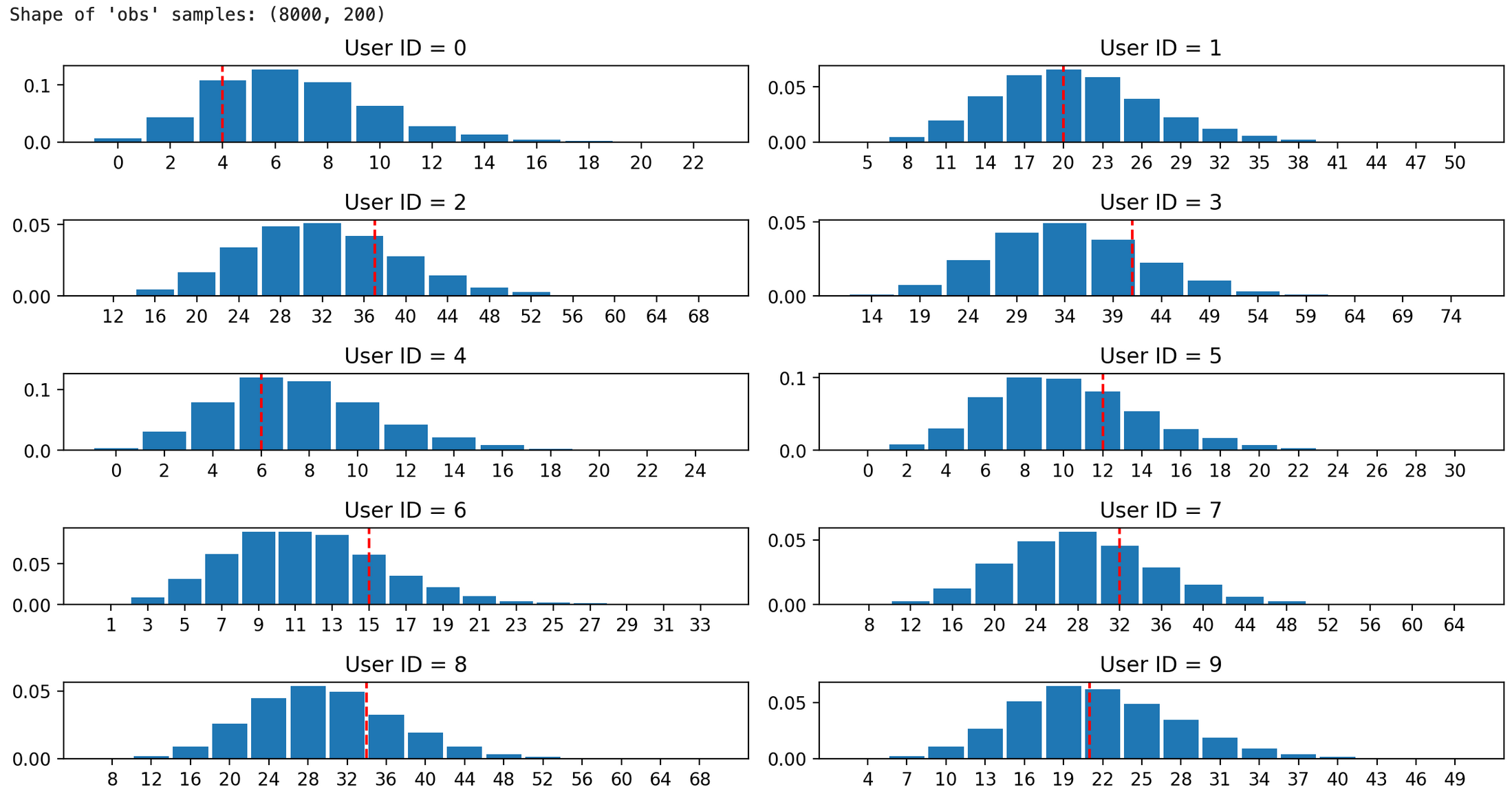
実際の観測値(点線) が、生成された分布(棒グラフ) の概ね平均値周辺に出ているため、モデルがある程度問題なくデータを再現できていることがわかる。
◆ TG/CG 結果の可視化
MCMC を使用して推定されたパラメータを基にして、テスト群(TG)とコントロール群(CG)の CV 数の推定分布を解析し、可視化する。
# MCMC 実行後のサンプルから beta0, beta1, s, r を取得
beta0_samples = mcmc_samples['beta0']
beta1_samples = mcmc_samples['beta1']
s_samples = mcmc_samples['s']
r_samples = mcmc_samples['r']
# TG と CG のグループインジケータ
tg_indicator = (group == 1)
cg_indicator = (group == 0)
# ポアソン分布の平均 mu を計算
b_samples = beta0_samples[:, None] + beta1_samples[:, None] * group
theta_samples = b_samples + r_samples
mu_samples = jax.numpy.exp(theta_samples)
# TG と CG の mu の平均を抽出
mu_samples_tg = mu_samples[:, tg_indicator]
mu_samples_cg = mu_samples[:, cg_indicator]
# 可視化
fig, ax = plt.subplots(figsize = (10, 6))
sns.kdeplot(mu_samples_tg.flatten(), ax = ax, fill = True, label = 'TG (Test Group)')
sns.kdeplot(mu_samples_cg.flatten(), ax = ax, fill = True, label = 'CG (Control Group)', alpha = 0.5)
ax.set_title('Estimated CV Counts Distribution for TG and CG')
ax.set_xlabel('Estimated CV Counts')
ax.set_ylabel('Density')
ax.legend()
ax.grid()
plt.show()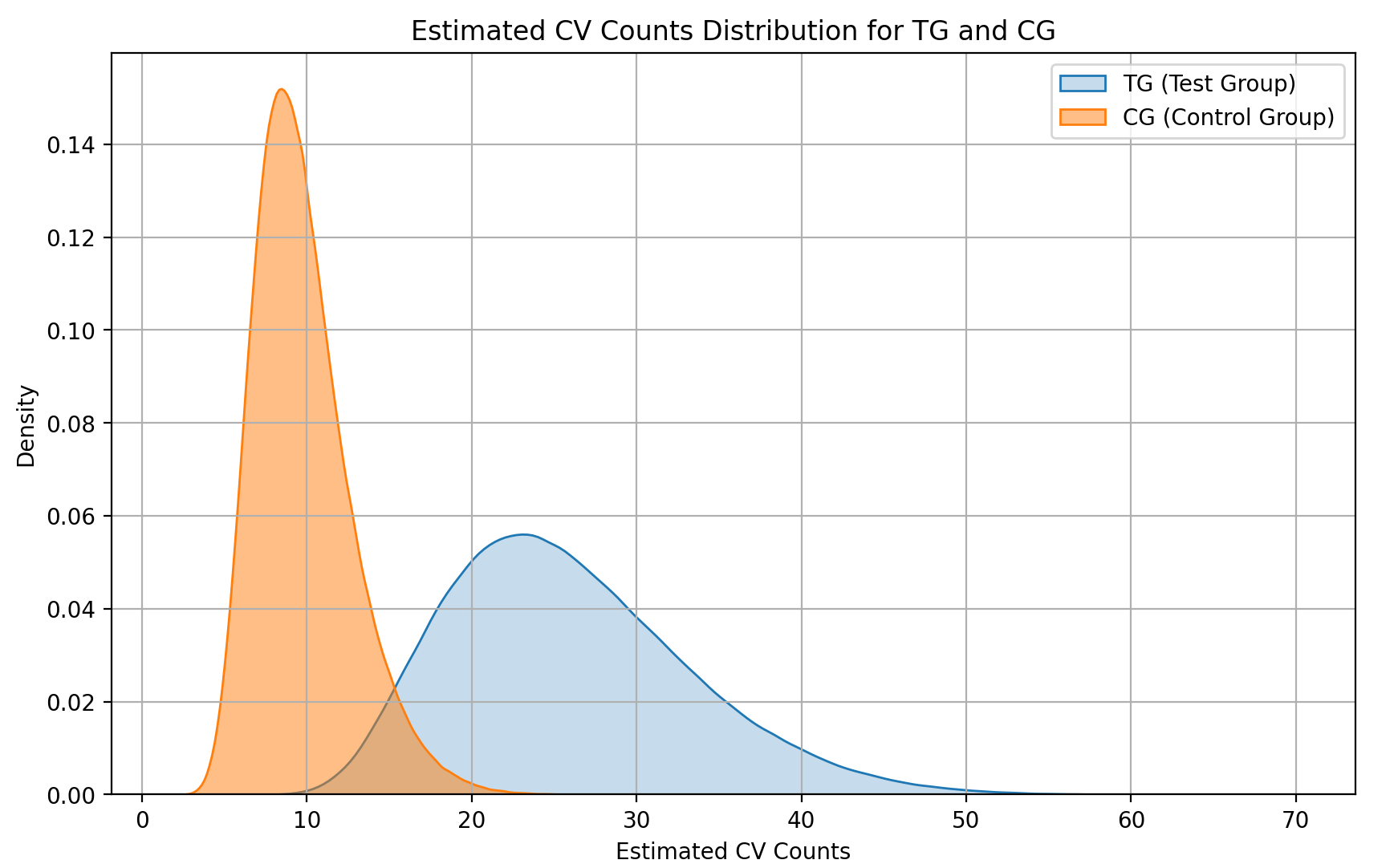
描画されたグラフの結果より、TG は CG に比べて CV 数が高く、実施した介入が効果的であったことが推定される。
A/B テストの具体的なシナリオ(施策介入によるCV影響)について、GLMM を用いて分析を行なった。 サンプルサイズが200ユーザーと、A/B テストとしては比較的小規模なデータに対して、ベイズモデルによる推定結果を適用することで、グループ間での効果の差を視覚的に評価することができた。